栈上分配
故名思议就是在栈上分配对象,栈上分配主要是指在Java程序的执行过程中,在方法体中声明的变量以及创建的对象,将直接从该线程所使用的栈中分配空间。 一般而言,创建对象都是从堆中来分配的,这里是指在栈上来分配空间给新创建的对象;其实目前Hotspot并没有实现真正意义上的栈上分配,实际上是标量替换。
栈上分配的好处一方面更加快速,另一方面是方法结束时对象也被回收了
private static int fn(int age) {
User user = new User(age);
int i = user.getAge();
return i;
}
User对象的作用域局限在方法fn中,可以使用标量替换的优化手段在栈上分配对象的成员变量,这样就不会生成User对象,大大减轻GC的压力,下面通过例子看看逃逸分析的影响。
public class JVM {
public static void main(String[] args) throws Exception {
int sum = 0;
int count = 1000000;
//warm up
for (int i = 0; i < count ; i++) {
sum += fn(i);
}
Thread.sleep(500);
for (int i = 0; i < count ; i++) {
sum += fn(i);
}
System.out.println(sum);
System.in.read();
}
private static int fn(int age) {
User user = new User(age);
int i = user.getAge();
return i;
}
}
class User {
private final int age;
public User(int age) {
this.age = age;
}
public int getAge() {
return age;
}
}
分层编译和逃逸分析在1.8中是默认是开启的,例子中fn方法被执行了200w次,按理说应该在Java堆生成200w个User对象
1、通过java -cp . -Xmx3G -Xmn2G -server -XX:-DoEscapeAnalysis JVM运行代码,-XX:-DoEscapeAnalysis关闭逃逸分析,通过jps查看java进程的PID,接着通过jmap -histo [pid]查看java堆上的对象分布情况,结果如下:
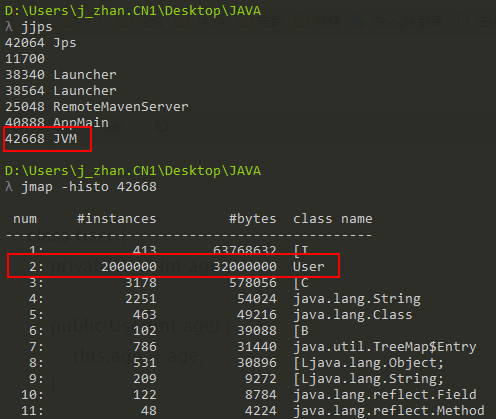
可以发现:关闭逃逸分析之后,User对象一个不少的都在堆上进行分配
2、通过
java -cp . -Xmx3G -Xmn2G -server JVM
运行代码,结果如下:
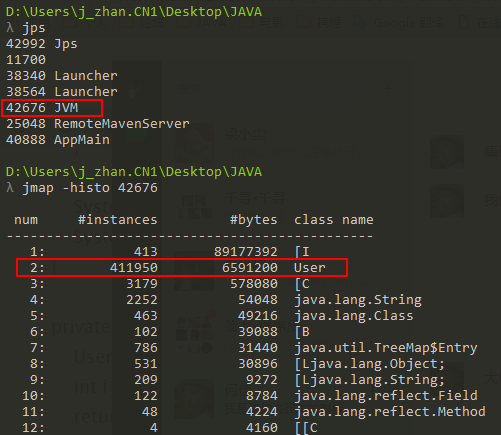
可以发现:开启逃逸分析之后,只有41w左右的User对象在Java堆上分配,其余的对象已经通过标量替换优化了。
3、通过
java -cp . -Xmx3G -Xmn2G -server -XX:-TieredCompilation
运行代码,关闭分层编译,结果如下
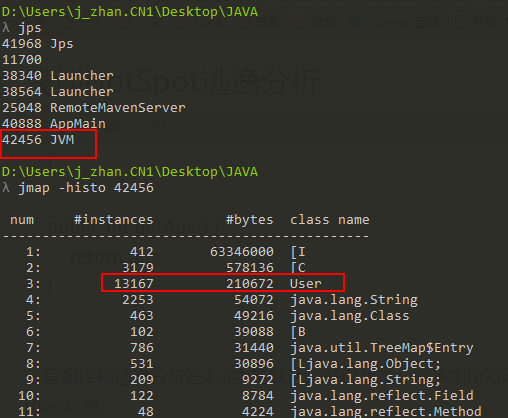
可以发现:关闭了分层编译之后,在Java堆上分配的User对象降低到1w多个,分层编译对逃逸分析还是有影响的